An up-to-date list is available on Google Scholar.
2025
-
×
![]()
Robust Molecular Property Prediction via Densifying Scarce Labeled Data
Jina Kim*, Jeffrey Willette*, Bruno Andreis*, and Sung Ju Hwang
2025
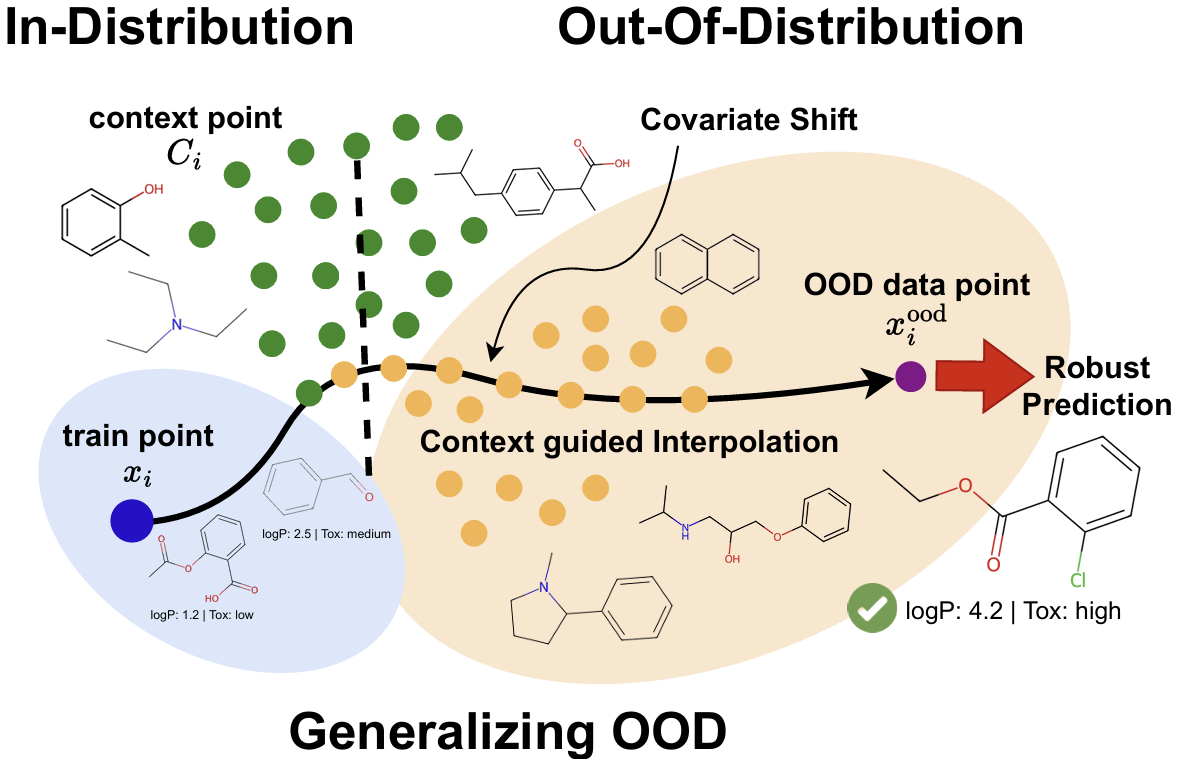
A widely recognized limitation of molecular prediction models is their reliance on structures observed in the training data, resulting in poor generalization to out-of-distribution compounds. Yet in drug discovery, the compounds most critical for advancing research often lie beyond the training set, making the bias toward the training data particularly problematic. This mismatch introduces substantial covariate shift, under which standard deep learning models produce unstable and inaccurate predictions. Furthermore, the scarcity of labeled data, stemming from the onerous and costly nature of experimental validation, further exacerbates the difficulty of achieving reliable generalization. To address these limitations, we propose a novel meta-learning-based approach that leverages unlabeled data to interpolate between in-distribution (ID) and out-of-distribution (OOD) data, enabling the model to meta-learn how to generalize beyond the training distribution. We demonstrate significant performance gains on challenging real-world datasets with substantial covariate shift, supported by t-SNE visualizations highlighting our interpolation method.
-
×
![]()
2024
-
×
![]()
SEA: Sparse Linear Attention with Estimated Attention Mask
Heejun Lee, Jina Kim, Jeffrey Willette, and Sung Ju Hwang
2024
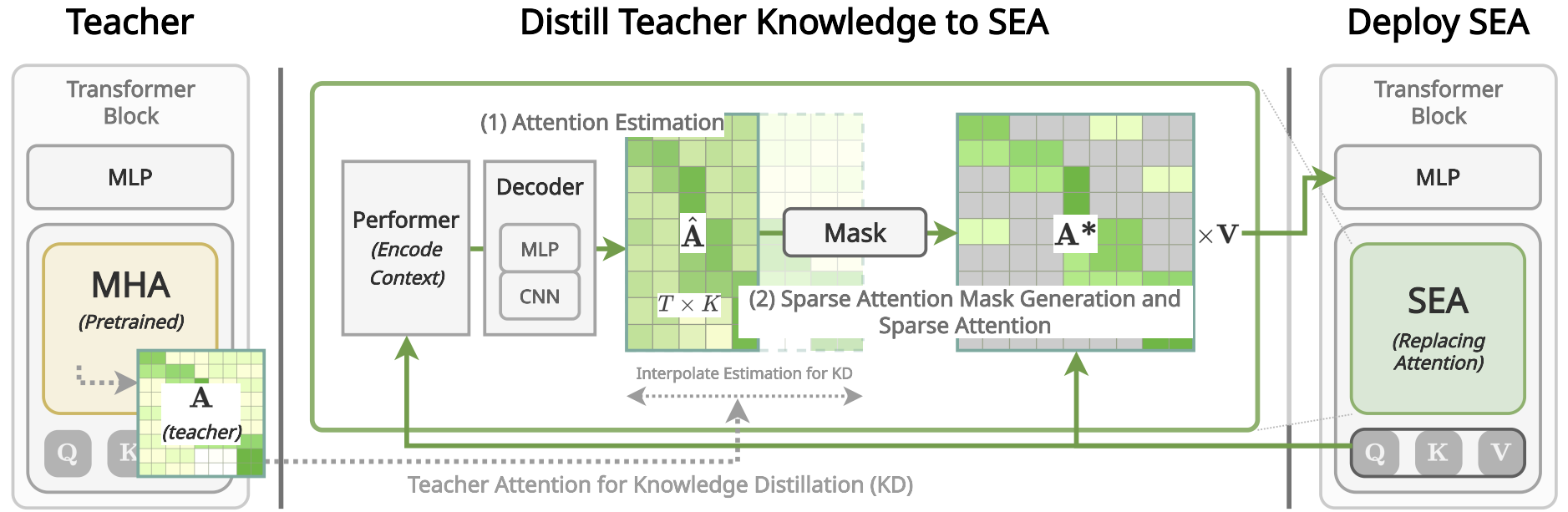
The transformer architecture has driven breakthroughs in recent years on tasks which require modeling pairwise relationships between sequential elements, as is the case in natural language understanding. However, long seqeuences pose a problem due to the quadratic complexity of the attention operation. Previous research has aimed to lower the complexity by sparsifying or linearly approximating the attention matrix. Yet, these approaches cannot straightforwardly distill knowledge from a teacher’s attention matrix and often require complete retraining from scratch. Furthermore, previous sparse and linear approaches lose interpretability if they cannot produce full attention matrices. To address these challenges, we propose SEA: Sparse linear attention with an Estimated Attention mask. SEA estimates the attention matrix with linear complexity via kernel-based linear attention, then subsequently creates a sparse attention matrix with a top-k selection to perform a sparse attention operation. For language modeling tasks (Wikitext2), previous linear and sparse attention methods show roughly two-fold worse perplexity scores over the quadratic OPT-1.3B baseline, while SEA achieves better perplexity than OPT-1.3B, using roughly half the memory of OPT-1.3B, providing interpretable attention matrix. We believe that our work will have a large practical impact, as it opens the possibility of running large transformers on resource-limited devices with less memory.